Como Scrapear Google Maps Gratis con Python
Te recomiendo que veas estos 2 vídeos:
Primeros pasos con Selenium en Python
Y Como conectar con hojas de calculo de Google Drive con Python
Aquí tenéis el código que he utilizado:
import gspread
import time
from datetime import datetime
import re
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
#PATH = '../Scrapeo/chromedriver'
#driver = webdriver.Chrome(PATH)
#driver.get("https://www.google.com")
class ScrapearGMaps:
data = {}
worksheet = {}
def __init__(self):
# Ruta de ChromeDriver
#self.driver=webdriver.Chrome(executable_path=r"C:\Users\nicolasmarin\Downloads\chromedriver_win32\chromedriver.exe")
self.driver = webdriver.Chrome(service=Service("/Users/luispalma/Documentos /Trabajo /Scrapeo/chromedriver"))
#self.driver = webdriver.Chrome(executable_path="../Scrapeo/chromedriver")
now = datetime.now()
today = now.strftime("%Y-%m-%d")
gc = gspread.service_account(filename='scraping-link-341712-b02b438fad16.json')
# Abrir por titulo
sh = gc.open("Empresas")
# Seleccionar primera hoja
self.worksheet = sh.get_worksheet(0)
def scroll_the_page(self, i):
try:
#section_loading = self.driver.find_element_by_class_name("section-loading")
section_loading = self.driver.find_element(By.CLASS_NAME, "section-loading")
while True:
if i >= len(self.driver.find_elements(By.CLASS_NAME, "place-result-container-place-link")):
#if i >= len(self.driver.find_elements(By.XPATH, '//*[@id="pane"]/div/div[1]/div/div/div[2]/div[1]/div[3]/div/a')):
actions = ActionChains(self.driver)
actions.move_to_element(section_loading).perform()
time.sleep(2)
else:
break
except:
pass
def get_geocoder(self, url_location): # gets geographical lat/long coordinates
try:
coords = re.search(r"!3d-?\d\d?\.\d{4,8}!4d-?\d\d?\.\d{4,8}",
url_location).group()
coord = coords.split('!3d')[1]
return tuple(coord.split('!4d'))
except (TypeError, AttributeError):
return ("", "")
def get_name(self):
try:
return self.driver.find_element(By.XPATH, "//h1[contains(@class,'header-title')]").text
except:
return ""
def get_address(self):
try:
return self.driver.find_element(By.CSS_SELECTOR, "[data-item-id='address']").text
except:
return ""
def get_phone(self):
try:
return self.driver.find_element(By.CSS_SELECTOR, "[data-tooltip='Copiar el número de teléfono']").text
except:
return ""
def get_website(self):
try:
return self.driver.find_element(By.CSS_SELECTOR, "[data-item-id='authority']").text
except:
return ""
def scrape(self, url):
try:
self.driver.get(url)
time.sleep(2)
element = self.driver.find_element(By.XPATH, "//button[.//span[text()='I agree']]")
element.click()
time.sleep(3)
for i in range(0,20):
self.scroll_the_page(i)
place = self.driver.find_elements(By.CLASS_NAME, "place-result-container-place-link")[i]
#place = self.driver.find_element(By.XPATH, '//*[@id="pane"]/div/div[1]/div/div/div[2]/div[1]/div[3]/div/a')[i]
place.click()
time.sleep(3)
name = self.get_name()
address = self.get_address()
phone_number = self.get_phone()
website = self.get_website()
coords = self.get_geocoder(self.driver.current_url)
email = ""
#if website != "":
# email = self.get_email('http://'+website)
print([name, address, phone_number, coords[0], coords[1], website, email])
row_index = len(self.worksheet.col_values(1)) + 1
self.worksheet.update('A'+str(row_index), name)
self.worksheet.update('B'+str(row_index), address)
self.worksheet.update('C'+str(row_index), phone_number)
self.worksheet.update('D'+str(row_index), coords[0])
self.worksheet.update('E'+str(row_index), coords[1])
self.worksheet.update('F'+str(row_index), website)
self.worksheet.update('G'+str(row_index), email)
element = self.driver.find_element(By.XPATH, "//button[.//span[text()='Volver a los resultados']]")
time.sleep(2)
element.click()
time.sleep(3)
except Exception as e:
print(e)
time.sleep(10)
#self.driver.quit()
return(self.data)
query = "veterinaria murcia"
url = "https://www.google.es/maps/search/"+query.replace(" ", "+")+"/"
gmaps = ScrapearGMaps()
print(gmaps.scrape(url))
Gracias Luis Enrique Palma por la actualización de este código.
También te puede interesar
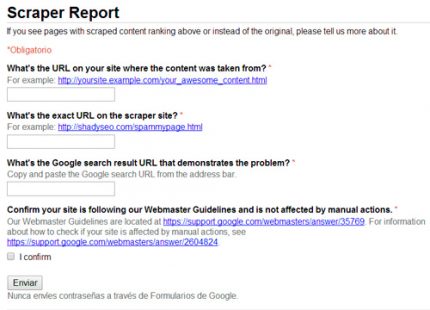
¿Qué hacer cuando te copian contenido? Google Scraper Report

Guía para spinear artículos en español

Calendario de Adviento SEO 2020
